Approximately a year and a half ago I discovered possibly the greatest programming language ever created. It happened while I was learning Go. Go was a fun language to learn, and coming from Java I appreciated one particularly awesome thing about it, I could compile a single binary, deploy and run it quickly and easily. Honestly, I hadn't realized how much I missed static binaries from C until I wrote a program in Go. There was no classpath, no monkeying with the default memory settings, no changing the default garbage collector. It was a nice language, but I had some problems. I missed generics, I missed typed and checked exceptions, and I couldn't help but feel like I was writing C but with a Garbage Collector (ok, easier than C and it has memory safety, big bonuses).
Then I started seeing Hacker News talking about this new language called Rust. It was marching toward a 1.0 release, I think it was at 0.8 when I first tried it out. With the help of Rust by Example I sat down and started learning the language, every time I wrote something there was an old hardened layer of programming tarnish that was wiped from my eyes. I had been shown the light, and there is no going back once you have been to the promised land. All of my colleagues have gotten tired of me talking about Rust... I definitely feel like a bible thumper sometimes. But at that point, I still didn't have anything substantial that I had written in Rust.
Then the computer gods said, "rewrite DNS"
CVE-2015-5477 struck BIND9, and it sounded pretty bad. After doing a little research it became somewhat clear, to me anyway, that BIND's biggest issue is that it is written in C; buffer overflows, out-of-bound array access, race conditions, etc. Take a look at the full list sometime, I think roughly 50% of those could have been avoided by using (safe) Rust. Is BIND9 the only DNS server out there? No. But it is the most widely deployed.
Before you call me a C hater, C is still probably my most favorite language.
It's pure, raw power. It's also a huge pain in the neck to debug, and there's
always that question, like what happens when you call strstr() on a non-null
terminated buffer? (yes, that was a fun one to track down, Kevin G.).
So I got started. Here is the first disappointing thing, there is no spec! What exists are rfc's dating back to 1987, specifically rfc1034 and rfc1035. Luckily the IETF marks the status of rfc's (the color coding at the top of the rfc page), and then it also forward and backward references to rfc's that update the current rfc or the ones which it obsolete's. My first job was to organize all of the rfc's that I planned on implementing (this list keeps changing by-the-way), obviously starting with rfc1035.
So then I got started, on-the-side; and by the way I have two small children and a full-time job, so on-the-side for me is not always the easiest time to come up with. Anywhere close to six hours a week is impressive.
A DNS client and server is born
From the README.md:
# trust-dns
A Rust based DNS server
The commit:
commit a3496cebf37c5e88bfbd4d7c5f036afe1d61cf6d
Author: Benjamin Fry <benjaminfry@me.com>
Date: Fri Aug 7 19:47:12 2015 -0700
Initial commit
It took me a few weeks to mostly complete rfc1035, the basics. The first
thing that I really started appreciating about Rust were the well defined
fixed size integers u8, u16, u32, u64. It was actually fun to parse
binary streams again! I've been working in Java mainly for the last decade,
I never found bit shifting intuitive in Java because there are only signed
integers. So this was like going back to C. Example DNS header parsing
(current as of this writing):
fn read(decoder: &mut BinDecoder) -> DecodeResult<Self> {
let id = try!(decoder.read_u16());
let q_opcd_a_t_r = try!(decoder.pop());
// if the first bit is set
let message_type = if (0x80 & q_opcd_a_t_r) == 0x80 { MessageType::Response } else { MessageType::Query };
// the 4bit opcode, masked and then shifted right 3bits for the u8...
let op_code: OpCode = ((0x78 & q_opcd_a_t_r) >> 3).into();
let authoritative = (0x4 & q_opcd_a_t_r) == 0x4;
let truncation = (0x2 & q_opcd_a_t_r) == 0x2;
let recursion_desired = (0x1 & q_opcd_a_t_r) == 0x1;
let r_z_ad_cd_rcod = try!(decoder.pop()); // fail fast...
let recursion_available = (0b1000_0000 & r_z_ad_cd_rcod) == 0b1000_0000;
let authentic_data = (0b0010_0000 & r_z_ad_cd_rcod) == 0b0010_0000;
let checking_disabled = (0b0001_0000 & r_z_ad_cd_rcod) == 0b0001_0000;
let response_code: u8 = 0x0F & r_z_ad_cd_rcod;
let query_count = try!(decoder.read_u16());
let answer_count = try!(decoder.read_u16());
let name_server_count = try!(decoder.read_u16());
let additional_count = try!(decoder.read_u16());
Ok(Header { id: id, message_type: message_type, op_code: op_code, authoritative: authoritative,
truncation: truncation, recursion_desired: recursion_desired,
recursion_available: recursion_available,
authentic_data: authentic_data, checking_disabled: checking_disabled,
response_code: response_code,
query_count: query_count, answer_count: answer_count,
name_server_count: name_server_count, additional_count: additional_count })
}
In each of those operations, I know exactly what is stored at each bit in each of those variables. I haven't gone back and changed it in some cases yet, but I've decided to start using this binary int format for checking bits, as I think it's more clear (as opposed to hex, which you can still see in the above code block. I need to clean that up, but if it ain't broke don't fix it):
let recursion_available = (0b1000_0000 & r_z_ad_cd_rcod) == 0b1000_0000;
If you're unfamiliar with rust, the result of the == operation is a boolean,
so the type of recursion_available is inferred. Also, I know my names look
funny, but each of those characters represents a bit, or more to help me visually
understand the bitfield I'm reading from.
In this bitshift example:
let op_code: OpCode = ((0x78 & q_opcd_a_t_r) >> 3).into();
If that operation happened on a 32bit boundary in Java, I'd be scratching my head
(actually a junit test would be easier) trying to remember if I needed >>> or
>>. I know the the answer, do you? In Rust there is no question. I will
be changing that above line to this, because I think it's much clearer:
let op_code: OpCode = ((0b0_1111_0_0_0 & q_opcd_a_t_r) >> 3).into();
I have to say, some of the ergonomics of Rust are awesome, like support for the
binary literal, Java just got this in 1.7. And the allowance of the _ for
visually separating portions of the literal is awesome, obviously most people
will usually use it as a replacement for , like let million = 1_000_000.
Disecting the above code a little more, that into() is a function from the
From trait implementation:
impl From<u8> for OpCode {
fn from(value: u8) -> Self {
match value {
0 => OpCode::Query,
2 => OpCode::Status,
4 => OpCode::Notify,
5 => OpCode::Update,
_ => panic!("unimplemented code: {}", value),
}
}
}
The above code shows a basic usage of match on integer and conversion to the
DNS OpCode enum. Notice that panic!, yeah, that's a logic bug.
I just filed the issue
for it, basically that panic! will crash the server if someone sends a bad
OpCode. This brings up an important point:
Rust does not prevent logic bugs
Rust prevents memory leaks[1], a subset of concurrency bugs, and others. It's not some magic bullet, but to not have to deal with memory access issues? Null pointer dereferences? Memory leaks[1]? Yeah, there was a reason I went to Java all those years ago. But now, I can go back to systems level programming with even better safety guarantees than Java!
That panic! is residual from when I was still getting comfortable with errors
in Rust. There are some error handling changes coming in Rust
that will make them easier, and error_chain
is greatly simplifies error type definitions, example.
I thought I had removed all panic! use cases from areas where they would be
encountered in live code paths, I never claimed to be perfect! (And writing
this post helped uncover a bug, so even if no one reads this, it was worth it).
You must deal with errors
Rust has made errors something you can not ignore. This is akin to checked
exceptions in Java (by the way, I'm in the camp of all Exceptions should be
checked). Rust uses a similar practice to Java in that, if you don't know how
to deal with an error, just rethrow it (best practice in Java). I'll be converting
that above From to something else soon, but let's look at the simplest form of
error handling:
let query_count = try!(decoder.read_u16());
This reads from the decoder byte stream the next u16. Of course this could fail,
because maybe there isn't enough bytes left to read a u16, or maybe it's a backed
by a TcpStream and the connection fails. But in this context, what can I do
with an error like that? Nothing really, there is no way to recover, so we rethrow.
That's what try! does, but in Rust it's not quite as simple as in Java, Rust
is statically typed. I won't get into error handling in this article, except to
point out a pain point with it, you can learn more about error handling here.
Rust has made the wise decision to force you to either propagate errors through
the Result type, or handle them. Because Rust is strongly typed, every function
call which returns an Error will need to compensate for all the inner functions called.
In the above example, we only need to deal with the DecodeError returned from
read_u16(), but in the Client::query() we return ClientError, which is
is just a union of a bunch of different types:
links {
super::decode_error::Error, super::decode_error::ErrorKind, Decode;
super::encode_error::Error, super::encode_error::ErrorKind, Encode;
}
While the type itself isn't growing because enums in Rust are more equivalent to
unions in C, the definition is expanding with each additional Error. The Client
ends up with the potential for DecodeError or EncodeError because it's obviously
performing both operations to send and then receive a message. The overhead of
dealing with this was daunting initially, but since better understanding the
problem, it's no longer a significant overhead, and again error_chain has
made it even easier.
Implementing rfc1035 was deceivingly easy
After a few iterations on the server code and authority, in September of 2015 I had a fully functional DNS server and client. But that's not what I set out to do. I set out to implement DNSSec, threw in DNSCrypt for fun, and wanted a dynamic library of which I could be proud.
This brings me to a lull point; DNSSec, how hard could it be? Remember I mentioned all those rfc's? Well DNSSec has gone through a few revisions, there is a trail of dead rfc carcasses that can be followed: rfc2065 (1997), obsoleted by rfc2535 (1999), obsoleted by rfc4033, rfc4034, and rfc4035 (2005), which have some very important clarifications in rfc6840 (2013). I missed one in there and fixed it recently, see issue #27. Which stems from this brilliant quote:
The guidance in the above paragraph differs from what has been
published before but is consistent with current common practice.
Item 3 of Section 6.2 of [RFC4034] says that names in both of these
RR types should be converted to lowercase. The earlier [RFC3755]
says that they should not. Current practice follows neither document
fully.
Did you catch that? No one implemented the spec properly, so now the spec is the implementation. I think that's a tail wagging the dog, right?
Anyway, back to the deceivingly easy bit; perhaps a picture will help:
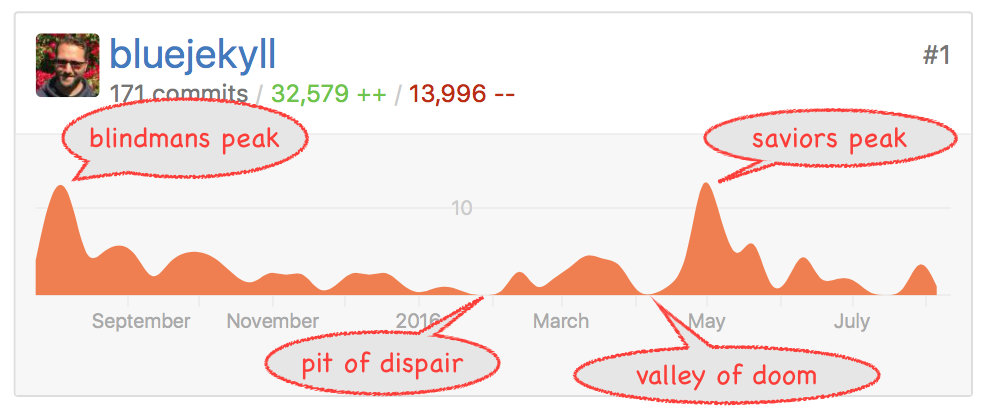
At blindmans peak, I was riding high. Loving Rust, nothing could stop me. I
had fun adding in support for things like the async io library mio
(I have plans to move to futures
when I have time). Then I decided it was
time to add DNSSec support. I had to read, and reread, all of the mentioned
rfcs, and some others. I started implementing, and then fell into the pit of
dispair as I tried and tried to get RRSIGs to first parse and then validate
properly. Only to discover that I needed additional methods
in the Rust OpenSSL port. After learning too much about OpenSSL (oh-my-dear-god I can
not unsee what I saw in there, the C, not Rust).
While in the pit of dispair, I considered many times giving up, with questions like; "What's the point?", "There are a ton of DNS servers out there, DJB's is rock solid. Am I really adding anything new?", "Is anyone even going to use this?" I have good answers to all of these, that will eventually make this implementation unique and offer features that answer long standing issues that I've had with DNS. So, I slogged through, and made some progress. Then I discovered that none of my signing logic was working properly. This brought me to the valley of doom, those questions I was asking myself, they only got louder and louder. "Stop wasting your time." But how could I stop? I made it this far, I must see it through. I needed to go back and reread all the DNSSec rfc's, and understand what I had screwed up.
Then I climbed saviors peak, which was hard. For any cyclists in the Bay Area, it's like the Three Bears ride in the East Bay, where the Baby Bear and Mamma Bear hills were tough, then Papa Bear hill has a false summit, and you still need to go up the huge last climb to get to the top. The downhill is totally worth it though, 45mph is thrilling on a bike.
Tests as a way of life
A feature that I found both surprising, and yet seems so obvious it should be
inherent to all languages, was the embedded tests
with a simple #[test] annotation which causes a test binary to be produced
with the cargo test command. In most languages you usually start by writing
a simple main() with a println!("hello world"), in Rust it's even easier to
start with a test. I have > 84% coverage, I can do better, but if you look at the
reports,
the most glaringly uncovered things are actually covered, but in integration
tests, cargo test -- --ignored, which I'm not currently running on Travis.
TCP servers on a free CI service seem like issues will follow. I've never been
a huge fan of aiming too much higher than 85-90% coverage, because I see
diminishing returns beyond that, as Dijkstra said:
testing can be a very effective way to show the presence of bugs,
but it is hopelessly inadequate for showing their absence
My favorite though is the ability to write threaded tests for server code, in Rust it's made even easier than similar practices I've used in Java:
#[test]
fn test_server_www_udp() {
let addr = SocketAddr::V4(SocketAddrV4::new(Ipv4Addr::new(127,0,0,1), 0));
let udp_socket = UdpSocket::bound(&addr).unwrap();
let ipaddr = udp_socket.local_addr().unwrap();
println!("udp_socket on port: {}", ipaddr);
thread::Builder::new().name("test_server:udp:server".to_string()).spawn(move || server_thread_udp(udp_socket)).unwrap();
let client_conn = UdpClientConnection::new(ipaddr).unwrap();
let client_thread = thread::Builder::new().name("test_server:udp:client".to_string()).spawn(move || client_thread_www(client_conn)).unwrap();
let client_result = client_thread.join();
assert!(client_result.is_ok(), "client failed: {:?}", client_result);
}
Teasing this apart, it creates two threads, one for the client, and one for the server.
Both use random local ports, so that we don't have any issues with binding to an
already used socket address. Then we start the server. Next we grab the server's
randomly assigned port, pass that into a new Client and start the client thread.
In tests, I see unwrap() and panic! as perfectly legit. The server thread is dead simple:
fn server_thread_udp(udp_socket: UdpSocket) {
let catalog = new_catalog();
let mut server = Server::new(catalog);
server.register_socket(udp_socket);
server.listen().unwrap();
}
I started writing tests like this in Java years ago for distributed systems, but this is much easier than the primitives I had at my disposal in Java. The client thread is where the meat of the test is:
fn client_thread_www<C: ClientConnection>(conn: C) {
let name = Name::with_labels(vec!["www".to_string(), "example".to_string(), "com".to_string()]);
println!("about to query server: {:?}", conn);
let client = Client::new(conn);
let response = client.query(&name, DNSClass::IN, RecordType::A).expect("error querying");
assert!(response.get_response_code() == ResponseCode::NoError, "got an error: {:?}", response.get_response_code());
let record = &response.get_answers()[0];
assert_eq!(record.get_name(), &name);
assert_eq!(record.get_rr_type(), RecordType::A);
assert_eq!(record.get_dns_class(), DNSClass::IN);
if let &RData::A(ref address) = record.get_rdata() {
assert_eq!(address, &Ipv4Addr::new(93,184,216,34))
} else {
assert!(false);
}
let mut ns: Vec<_> = response.get_name_servers().to_vec();
ns.sort();
assert_eq!(ns.len(), 2);
assert_eq!(ns.first().unwrap().get_rr_type(), RecordType::NS);
assert_eq!(ns.first().unwrap().get_rdata(), &RData::NS(Name::parse("a.iana-servers.net.", None).unwrap()) );
assert_eq!(ns.last().unwrap().get_rr_type(), RecordType::NS);
assert_eq!(ns.last().unwrap().get_rdata(), &RData::NS(Name::parse("b.iana-servers.net.", None).unwrap()) );
}
If you notice, the function is declared as generic over the ClientConnection type,
this allows for a monomorphic function call that works with both TCP and UDP clients,
meaning one test for both TCP and UDP servers and clients. I put the code here for an
example, you can see the rest of the tests in the server.rs
source.
I know that looking at the Name::with_labels() call looks a little clumsy, I want
to clean that up, but haven't quite settled on some ideas around String interning
that I want to play with. In point of fact, my labels implementation in Name is
one of the very few places where I want a garbage collector in Rust, that desire might
go away once I have a better way of performing an intern.
So where is Trust-DNS now?
It's currently not used in production (as far as I know). I've put a lot of work into validating correctness of what is going on, and have had help, more is always welcome. I want to get a DNS fuzzer running against it to really pound on it, and then get some benchmark and comparison tests against other servers.
Things I'm proud of: DNSSec support, with client side validation, and zone signing with local keys. Server and Client both have support for dynamic DNS with SIG0 validation and auth. Journaling support on the Server with sqlite. EDNS is supported for greater than 512 byte UDP packets (defaults to 1500).
I'm currently in the middle of working on DNSCrypt[2], and then I'll be moving on to some more fun ideas. I never imagined it would be this long of a journey, but it's only just beginning, and along with learning such a spectacular language it's totally worth it. Thank you to everyone who spends so much time perfecting Rust and it's ecosystem, you have reinvigorated my joy of programming.
(I'll try to post more regularly on progress)
- 1) I got a lot of feedback on Rust not preventing memory leaks.
For me, in my experience it's at least as good as Java, meaning you have to go
out of your way to cause a situation where a variable will not be dropped. This
can happen in safe code. Examples would be ever growing Vectors, or poor usage
of
std::mem::forgetwhich tells Rust not to call drop and cleanup the memory. When would you want to do this? I've used this when passing objects back to C through FFI methods, there are other cases. If you want to read a ton, checkout this post: https://github.com/rust-lang/rfcs/pull/1066. I left what I wrote mostly so that people could come to it, and then read this, think about it, and then realize no language actually prevents memory leaks, but Rust is memory safe... - 2) After some offline discussion and this issue: Feature request: "RFC 7858, DNS over TLS #38", I'm very much thinking of shelving my work on DNSCrypt and focusing instead on DNS over TLS