When I wrote Taking TRust-DNS IntoFuture regarding the initial implementation of TRust-DNS over the Tokio async library, one of the first questions I was asked (by one of the maintainers): "is it the fastest implementation out there?" Sadly the answer was no, not by a long shot. TRust-DNS was 400µs and BIND9 100µs (as measured on my getting older laptop, YMMV). 300µs is a miniscule amount of time to people, but to computers that's a lot of time. Given that inside datacenters a full round trip is 500µs, spending an extra 300µs on the node serving up the IP address of the service you're trying to connect to is not insubstantial. Shouldn't we be able to beat BIND? Of course we should. The rest of this post is going to document the path to get there, and some that I tried but didn't follow. As my knowledge of Rust has grown, it seemed like a good time to try some new things. It's an arbitrary goal, but it's a fun one.
Measure First, Cut Second
Where are we right now? Well, after starting to use better practices around references and clones in the project, this number is down to 250µs. Why did this improve so much from the 400µs? I really have no idea. It could be improvements in the compiler and such, but that would surprise me if it made that big of a difference. My guess is that after writing that previous post and being disappointed in the performance, I started practicing better code style around not cloning data and better utilizing reference passing, etc. Our target is being set by BIND9's performance[1]:
test bind_udp_bench ... bench: 69,960 ns/iter (+/- 7,207)
69µs, that's the number we need to beat (best time produced after multiple runs of the benchmark test, due to network stack, etc. this has not always produced a consistent number).
I have some theories on where I should spend my time in trying to speed things up. My guess is that for the records stored in the authority, they are not stored in serialized form. This means that the records are always serialized for each response. If we pre-serialize I think this should get us the biggest win. The next is that buffers are allocated on each request. My guess is that if this is replaced with a fixed-sized pool of buffers, like an arena. The next thing I'm going to guess is that for each set of records we return, there is a new Vec<&Record> returned. Getting rid of this might speed things up. I want to play with some ideas around chained iterators instead of creating the temporary Vecs. Some other ideas are to go through and replace a lot of the Box<Future<...>> results from a lot of methods throughout the library. But which should we target first? There are a million good quotes on this, but I like this one: "Human beings, even experienced programmers, are very poor at predicting (guessing) where a computation will bog down." from C2. So I've made my guesses, but given that I'm human, we should find a way to get the machine to tell us if we're correct.
I liked this post about optimizing Rust from jFransham. Lots of good advice in there, and it links to this great post: Rust Performance: A story featuring perf and flamegraph on Linux, but that's Linux, my dev machine in macOS. So we'll be using Carol Nicol's, Rust Profiling with Instruments and FlameGraph on OSX: CPU/Time. I was concerned that switching to the system allocator, as she recommends in that article, would have an effect on the benchmark. If it does, it's not one that showed up in my testing.
Following Carol's instructions, I launched Instruments and registered the named binary from TRust-DNS. Configured with the same options I was using in the bench tests, it was ready to go. I just needed to pick a stable UDP port to use. Back to the bench test itself with a hard-coded port and stopped launching named in the test. After I ran the test, I was going to be excited to see all of this profile information to tell me where to fix things. I ran the test and:
test trust_dns_udp_bench ... bench: 100,892 ns/iter (+/- 148,959)
wait... hold on a second here, 100µs? This was definitely not expected. TRust-DNS is almost as fast as BIND9. So I reviewed the startup, initially thinking it was the Stdio::piped arg for stdout on the Command. It was not that, but the answer does lie in the initialization:
let mut named = Command::new(&format!("{}/../target/debug/named", server_path))
.stdout(Stdio::null())
.arg(&format!(
"--config={}/tests/named_test_configs/example.toml",
server_path
))
.arg(&format!(
"--zonedir={}/tests/named_test_configs",
server_path
))
.arg(&format!("--port={}", test_port))
.spawn()
.expect("failed to start named");
Take a look at the path to the TRust-DNS command, "{}/../target/debug/named", notice debug? Yup... making that release means that we're using the optimized target. Let's see what the time is with the fixed version:
test trust_dns_udp_bench ... bench: 79,274 ns/iter (+/- 9,626)
That's significantly better, and brings us within 10µs of BIND9. That was a sad oversight; I've been underselling TRust-DNS' performance for over a year.
Collecting Some Data
Now that we're viewing the correct binary, we can actually start looking at how to make it faster. Here's a screenshot of the Instruments capture, which has a lot of options. I've narrowed the view to only the time where the test was running.
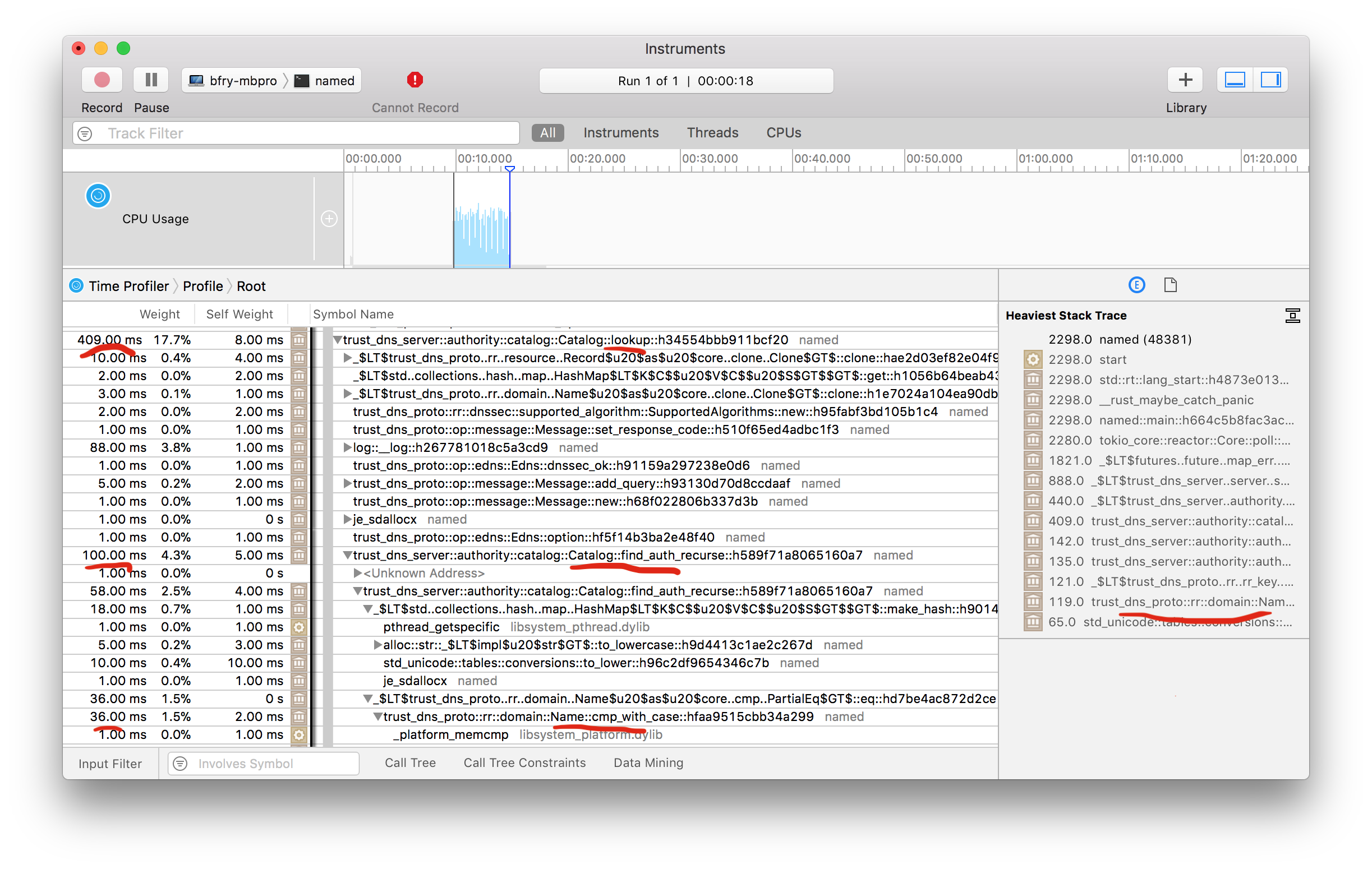
I've underlined some things to draw your attention to them. You'll notice a few things. First on the left is the time spent in different calls. There are some that I avoided in this view. For example, the time spent in I/O. Most of the time is actually spent in UdpSocket::recv_from and UdpSocket::send_to, which we expect, this is mainly a network bound process after all. The other time I'm ignoring is the time spent in env_logger, as I see logging as important for monitoring the process.
So what does that leave for us? Looking at that image, on the right is the tool helpfully drawing your attention to the most expensive call stack in the capture. Following through from the left, most of the expense in the call is in the lookup of the record from the Authority. You'll notice in the underlined calls that we recorded, Catalog::lookup eventually ends up relying on Name::cmp_with_case. I've only shown a snippet, but the call into this function happens a lot. It's not surprising, during a lookup the Query::name is one of the three components we're using for the search, and it's the most complex. Names are the human interface into DNS (arguably it's most important feature), and for better or worse, they are generally case-insensitive. On the good side this means that someone typing WWW.GOOGLE.COM into their browser, will get the same result as if they type www.google.com; on the bad side it means that we have to do a more complex string comparison where we convert to lowercase while comparing during our search for records in the Authority (I'll be referring to other findings from the instruments tool throughout this post). I wonder if this is a regret on the side of the original RFC authors? [2]
Let's look at this function:
pub fn cmp_with_case(&self, other: &Self, ignore_case: bool) -> Ordering {
if self.labels.is_empty() && other.labels.is_empty() {
return Ordering::Equal;
}
// we reverse the iters so that we are comparing from the root/domain to the local...
let self_labels = self.labels.iter().rev();
let other_labels = other.labels.iter().rev();
// here were taking all the labels from the name
for (l, r) in self_labels.zip(other_labels) {
if ignore_case {
// for each we to_lowercase, hey, this allocates a new String each time!
match (*l).to_lowercase().cmp(&(*r).to_lowercase()) {
o @ Ordering::Less | o @ Ordering::Greater => return o,
Ordering::Equal => continue,
}
} else {
match l.cmp(r) {
o @ Ordering::Less | o @ Ordering::Greater => return o,
Ordering::Equal => continue,
}
}
}
self.labels.len().cmp(&other.labels.len())
}
The to_lowercase is occurring on each label portion of the name, and if you look at the docs for String::to_lowercase, this allocates a new String. This post recently made the rounds, Fast software is a discipline, not a purpose, what's the very first bullet point? "Avoid unnecessary memory allocations" and then the next one, "Avoid multiple passes over the data when one would do". By performing the to_lowercase while evaluating all names, we are basically breaking both of these rules. Well, let's see if we can fix that.
I created 3 variations for comparing names:
-
short
"com" == "COM" // case insensitive"com" != "COM" // case sensitive"com" == "com" // case sensitive -
medium, about average length
"www.example.com" == "www.EXAMPLE.com" // case insensitive"www.example.com" != "www.EXAMPLE.com" // case sensitive"www.example.com" == "www.example.com" // case sensitive -
long
"a.crazy.really.long.example.com" == "a.crazy.really.long.EXAMPLE.com" // case insensitive"a.crazy.really.long.example.com" != "a.crazy.really.long.EXAMPLE.com" // case sensitive"a.crazy.really.long.example.com" == "a.crazy.really.long.example.com" // case sensitive
Here are the runtimes:
running 9 tests
test name_cmp_long ... bench: 2,178 ns/iter (+/- 387)
test name_cmp_long_case ... bench: 33 ns/iter (+/- 9)
test name_cmp_long_not_eq ... bench: 11 ns/iter (+/- 2)
test name_cmp_medium ... bench: 1,052 ns/iter (+/- 196)
test name_cmp_medium_case ... bench: 18 ns/iter (+/- 4)
test name_cmp_medium_not_eq ... bench: 10 ns/iter (+/- 3)
test name_cmp_short ... bench: 255 ns/iter (+/- 86)
test name_cmp_short_case ... bench: 8 ns/iter (+/- 5)
test name_cmp_short_not_eq ... bench: 6 ns/iter (+/- 1)
Those case insensitive checks are really expensive! What are our options here? I see two options: make the comparison itself not allocate new Strings - this would be easier; Make a new type of Name like LowerName or such - this would be harder. The latter would require a lot more effort in terms of refactor call sites in the library, and I'd prefer to try and keep these changes performant, but maintain some simplicity in the code. So we'll try option 1 first, the code isn't all that different. The change is in the for loop from above, we just add an inner loop on chars:
for (l, r) in self_labels.zip(other_labels) {
if ignore_case {
// just grab the chars, and then do the lower case setting:
for (l, r) in l.chars().zip(r.chars()) {
match l.to_lowercase().cmp(r.to_lowercase()) {
o @ Ordering::Less | o @ Ordering::Greater => return o,
Ordering::Equal => continue,
}
}
} else {
match l.cmp(r) {
o @ Ordering::Less | o @ Ordering::Greater => return o,
Ordering::Equal => continue,
}
}
}
And the new timings:
running 9 tests
test name_cmp_long ... bench: 1,332 ns/iter (+/- 273)
test name_cmp_long_case ... bench: 31 ns/iter (+/- 7)
test name_cmp_long_not_eq ... bench: 10 ns/iter (+/- 2)
test name_cmp_medium ... bench: 686 ns/iter (+/- 355)
test name_cmp_medium_case ... bench: 18 ns/iter (+/- 8)
test name_cmp_medium_not_eq ... bench: 10 ns/iter (+/- 0)
test name_cmp_short ... bench: 157 ns/iter (+/- 5)
test name_cmp_short_case ... bench: 8 ns/iter (+/- 3)
test name_cmp_short_not_eq ... bench: 6 ns/iter (+/- 3)
That's better, we've almost doubled the speed. After running this attempt through our benchmark it made no difference to the overall time. Ok, slightly more extreme variation, let's store a lowercased version of the labels internally in Name on demand. I've added an extra field to Name with all the labels lowercased, and to simplify the object changed the labels from Vec<Arc<String>> to just Vec<String>. This is a little ugly, something I can go back and cleanup:
pub struct Name {
is_fqdn: bool,
labels: Vec<String>,
// Now it's stored separately
lower_case_labels: Vec<String>,
}
The reason I think that's ugly is that we now have an entire class of potential bugs related to it. When adding a label, we need to add it to both, same with removing. Luckily there were a lot of unit tests covering Name, so the likely hood of missing simple issues here is low, but still. Here are the new times:
running 9 tests
test name_cmp_long ... bench: 30 ns/iter (+/- 4)
test name_cmp_long_case ... bench: 29 ns/iter (+/- 2)
test name_cmp_long_not_eq ... bench: 10 ns/iter (+/- 2)
test name_cmp_medium ... bench: 16 ns/iter (+/- 2)
test name_cmp_medium_case ... bench: 16 ns/iter (+/- 6)
test name_cmp_medium_not_eq ... bench: 9 ns/iter (+/- 1)
test name_cmp_short ... bench: 7 ns/iter (+/- 0)
test name_cmp_short_case ... bench: 7 ns/iter (+/- 1)
test name_cmp_short_not_eq ... bench: 6 ns/iter (+/- 1)
Now that is much better! Again, after running the overall benchmark, we didn't see a difference. Maybe by removing Arc from the labels, we have too many clones of Name now? Time to throw it into the profiler again... (time passes) ...after perusing the profiler output, there were still a lot of to_lowercase calls showing up. But even with that change, it's made no difference to the overall benchmark.
Revisiting String Duplication (1 Month Later)
After reaching the end of this expedition (continue reading), I came back and decided to revisit the hack that I put in place above, specifically the duplicate Strings. So I reverted the changes to name, so that we can take a different approach. I thought it would be fun to see if to_lowercase on Name could be faster if we performed the lowercase operation when needed, otherwise just a simple clone of the Arc to each label would suffice. I wrote some benchmarks to start (the no means that there is no difference between the lowercased form and the non-lowercased form):
test name_no_lower_long ... bench: 699 ns/iter (+/- 29)
test name_no_lower_short ... bench: 242 ns/iter (+/- 34)
test name_to_lower_long ... bench: 705 ns/iter (+/- 33)
test name_to_lower_short ... bench: 229 ns/iter (+/- 52)
And then after only to_lowercasing the label if it's required (code follows):
test name_no_lower_long ... bench: 69 ns/iter (+/- 32)
test name_no_lower_short ... bench: 36 ns/iter (+/- 17)
test name_to_lower_long ... bench: 340 ns/iter (+/- 98)
test name_to_lower_short ... bench: 188 ns/iter (+/- 69)
That's a nice improvement, so I'll keep the code:
pub fn to_lowercase(&self) -> Self {
let mut new_labels: Vec<Rc<String>> = Vec::with_capacity(self.labels.len());
for label in &self.labels {
if label.chars().any(|c| !c.is_lowercase()) {
new_labels.push(Rc::new(label.to_lowercase()));
} else {
new_labels.push(Rc::clone(label))
}
}
Name{ is_fqdn: self.is_fqdn, labels: new_labels }
}
But, when searching for matches, and storing the Keys in the Authority we don't care about case at all... So I created a LowerName, that guarantees that the Name is already lowercased where we need it to be:
# comparison
test name_cmp_long ... bench: 35 ns/iter (+/- 11)
test name_cmp_long_case ... bench: 35 ns/iter (+/- 5)
test name_cmp_medium ... bench: 19 ns/iter (+/- 0)
test name_cmp_medium_case ... bench: 19 ns/iter (+/- 1)
test name_cmp_short ... bench: 8 ns/iter (+/- 1)
test name_cmp_short_case ... bench: 8 ns/iter (+/- 0)
# to_lowercase
test name_no_lower_long ... bench: 2 ns/iter (+/- 0)
test name_no_lower_medium ... bench: 2 ns/iter (+/- 0)
test name_no_lower_short ... bench: 2 ns/iter (+/- 1)
test name_to_lower_long ... bench: 2 ns/iter (+/- 0)
test name_to_lower_medium ... bench: 2 ns/iter (+/- 0)
test name_to_lower_short ... bench: 2 ns/iter (+/- 0)
The to_lowercase section is a joke. The name is already lowercased (and type safe at that). It's just doing a stupid check to make sure the benchmark isn't removed entirely. I won't be adding this useless benchmark. Obviously, I'm not really expecting a better result than the former case of compares that were case sensitive, but this makes sure that all cases of to_lowercase are verifiably not needed because of the new LowerName type. In addition to that, I've created a LowerQuery which is just a wrapper around LowerName, DNSClass, and RecordType then used that as the type of the parameter for the API into the Catalog and Authority. We still have a flexible programming environment when working with these structures.
Don't Have a Cow
Ok, truth be known, I really wanted to use Cow for all of this. Cow is our friend, and this String method in particular:
fn from_utf8_lossy(v: &'a [u8]) -> Cow<'a, str> {...}
There is a concern here, which is that this lossy method will result in non-valid utf8 characters being converted to �. This seems like an acceptable loss for now. It's not incorrect per sé. Obviously the other option here would be to just directly use [u8], but that would mean we'd lose access to Rust's nice to_lowercase, and why would we want to do that?
So I had created a new Name type, DecodedName<'r> which shared a lifetime with the request buffer backing the BinDecoder<'r>. This meant that if the buffer was proper utf8 and in addition lowercase, we wouldn't have needed to allocate anything for query names. But I ran into an issue: all of the RecordSets are stored in a BTreeMap keyed off of RrKey which is just a wrapper type of Name and RecordType. BTree::get has this interface:
fn get<Q>(&self, key: &Q) -> Option<&V> where
K: Borrow<Q>,
Q: Ord + ?Sized,
I could not for the life of me figure out how get a Name implement a Borrow<Q> where Q would have been DecodeName<'r> (or RrKey to DecodedRrKey<'r> which is what would have been needed). After working through a lot of ideas, I gave up on this approach. Maybe there's a way to do it with unsafe and std::mem::transmute, but I'm trying to keep all unsafe usage out of the TRust-DNS libraries (and have been successful up to this point). So I leave that as a challenge to someone who knows Rust better than I.
Surprises Lurking in Old Code
The next thing on this list is the serialization. It turns out half our time in the RequestHandler is spent serializing and for the big ticket item, serialization of the Records:
374.2ms 19.8% 624 19.5% 2.5 _$LT$trust_dns_server..server..server_future..ServerFuture::handle_request
148.7ms 7.8% 237 7.4% 5.7 trust_dns_server::server::request_stream::ResponseHandle::send
...
57.9ms 3.0% 95 2.9% 6.0 _$LT$trust_dns_proto..rr..resource..Record::emit
29.5ms 1.5% 48 1.5% 0.6 trust_dns_proto::rr::record_data::RData::emit
...
14.9ms 0.7% 23 0.7% 2.4 _$LT$trust_dns_proto..rr..resource..Record::clone
The last one surprised me, though, I spent a lot of time making sure that references were passed to individual records stored in the Authority. Turns out, in some of the original code, I had been lazy and had delayed making a borrowed version of Message. This means all the records inserted into the response Message ended up being cloned. It's not the most substantial cost of the send, but it's ugly in Catalog::lookup:
pub fn lookup(&self, request: &Message) -> Message {
let mut response: Message = Message::new();
// ...
// CLONE!!
// ...
response.add_queries(request.queries().into_iter().cloned());
// ...
for query in request.queries() {
if let Some(ref_authority) = self.find_auth_recurse(query.name()) {
let records = authority.search(query, is_dnssec, supported_algorithms);
if !records.is_empty() {
response.set_response_code(ResponseCode::NoError);
response.set_authoritative(true);
// ...
// CLONE!!
// ...
response.add_answers(records.iter().cloned());
// ...
}
// ...
}
// ...
}
// ...
}
Message was one of the first things written in the library, I had not yet become as comfortable with the type system in the language enough to understand[3] the patterns for writing generics over owned and unowned data in Rust. But now, I get to clean this 💩 up. By introducing a new Message type, MessageResponse, there is now a zero (less) copy Message type:
pub struct MessageResponse<'q, 'a> {
header: Header,
queries: Option<&'q Queries<'q>>,
answers: Vec<&'a Record>,
name_servers: Vec<&'a Record>,
additionals: Vec<&'a Record>,
sig0: Vec<Record>,
edns: Option<Edns>,
}
This MessageResponse type only has strong ownership of the data it requires, things like sig0 and EDNS, which are dynamically constructed per request. Notice this has two lifetimes (Message did not have any), 'q and 'a. 'q represents the request lifetime of Queries<'q> which itself is a new type for this change. Queries<'q> carry a reference to the request buffer's query section, which is now used to stream those directly back in the encoding of the response. This means that we only need to decode queries, but not encode them so much as just write the exact same bytes to the response packet (this is jumping ahead a little bit, see below for the discovery of the expense of Query serialization). The 'a is the lifetime associated with the answers. These lifetimes are associated with Authority in the Catalog of the Server. There used to be a clone of each of those answer Records, but now we share a reference back to the Authority so there is no clone.
To get the numbers associated to this change, I hacked the code into a really ugly state. It's a testament to Rust that it still works. Many other languages I'm sure I would have introduced some bugs, but this still passes all the tests. We are getting closer to our goal. I am a little disappointed with a particular part of this change, though. In the Catalog there is a ReadWriteLock which wraps the Authority serving records. Originally, this would construct a fully owned Message for response. Now, if you notice, most of the Records in MessageResponse are references with associated lifetimes. Those lifetimes are from the inner Authority record sets in which they are stored, but because they are returned in a critical section of the ReadWriteLock during lookup, we can no longer pass the MessageResponse out from RequestHandler. The reason this is disappointing is more obvious in the change to the request_handle signature:
fn handle_request(&self, request: &Request) -> Message;
becomes:
fn fn handle_request<'q, 'a>(&'a self, request: &'q Request, response_handle: ResponseHandle) -> io::Result;
Before there was a compile time guarantee that a handler would return a Message to send back to a client. Now, there is no compilation validation that a Message will always be sent. I'd really like to continue to enforce this guarantee, but haven't yet come up with a clear solution. At least something is required to be returned, but the former was a stronger guarantee. I may add a type that can only be created by ResponseHandle when a response is sent that must be returned, which may be an acceptable compromise.
Serialization is Expensive
Now we get into some serialization issues. Looking through the instruments run data again we have this:
32.0ms 2.3% 32 2.3% 0.0 trust_dns_server..authority..message_response..MessageResponse::emit_queries
22.0ms 1.6% 22 1.6% 1.0 trust_dns_server..authority..message_response..MessageResponse::emit_name_servers
12.0ms 0.8% 12 0.8% 1.0 trust_dns_proto..rr..resource..Record::emit
12.0ms 0.8% 12 0.8% 2.0 trust_dns_server..authority..message_response..MessageResponse::emit_answers
Once these records are stored in the Authority they really don't change, so why not just pre-serialize them? Digging into those calls, it turns out that our friend Name is the most expensive thing to serialize. But the first thing we can quickly do, is preserve the bytes on the Querys (as already briefly mentioned), we have that passed in from the Request. The serialization of these sections of the Message don't even appear in the capture any more as hotspots. I should take a look at how EDNS is being serialized, but first I have a lot of cleanup of these changes to do. I considered pre-serializing all the Records as stored in the Authority, but this would make label compression harder and also make dynamic updates more difficult for things like compare-and-swap operations. It would be a bummer to increase the speed of the server only to discover that we've increased packet size dramatically and also made maintenance of the project much worse (see Revisiting all that String duplication above).
Stop Creating Intermediary Objects
For EDNS it turns out that we're first creating a Record and then serializing that record. The EDNS object is generally constructed per connection, the cost is surprising:
14.0ms 1.2% 14 1.2% 1.0 trust_dns_proto::rr::rdata::opt::emit
12.0ms 1.0% 12 1.0% 8.0 trust_dns_proto::rr::rdata::opt::EdnsOption::from
For this one, I'm going to get rid of the intermediate construction of the Record object and just stream the data directly. While fixing this code, I discovered that I was doing a pretty expensive operation to temporarily capture the rdata portion of the Record as a Vec<u8> just so that I could get its final size (in DNS the RData of a Record is preceded by a u16 and then the binary data); this is a huge waste (and it happens during all Record serialization, not just EDNS). To get around this, I've added a new interface to the BinEncoder that allows you to capture a place in the buffer, and then write back to it when done. This should allow for a lot of serialization routines to be improved. It mimics the new unstable feature in the stdlib, Place.
After fixing EDNS, I went back and applied this fix to all Record serialization.
Fixup Label Compression
Label compression in DNS is pretty straight forward: basically don't duplicate names already written to the packet. This was being tracked in the BinEncoder with a HashMap storing labels which would be inspected for each label being added. This was defined as owning Strings (I didn't show the things which directed me here from Instruments' output, but it was clear that this was expensive from that tool):
name_pointers: HashMap<Vec<String>, u16>
It made encoding labels into the message an expensive process because each String would be cloned into the map (and a Vec) allocated for each set of labels. We can simplify this to just store offsets into the buffer being written, and be much more memory/allocation efficient:
name_pointers: Vec<(u32, u32)>
Now when processing labels, we always write the set of labels to the buffer, then take slices into the buffer and compare those to see if they can be replaced with an excerpt from another already serialized Name:
pub fn emit_as_canonical(&self, encoder: &mut BinEncoder, canonical: bool) -> ProtoResult<()> {
/// ... canonical case not shown ....
// our set of labels from this Name
let labels: &[Rc<String>] = &self.labels;
// start index of each label
let mut labels_written: Vec<u32> = Vec::with_capacity(labels.len());
// we first write all our labels to the buffer,
// this get's us the encoded form we're going to use for the &[u8] comparison to other already serialized labels
for label in labels {
// track the labels position in the buffer
labels_written.push(encoder.offset());
// now write the label
encoder.emit_character_data(label)?;
}
// we've written all the labels to the buf, the current offset is the end
let last_index = encoder.offset();
// now search for other labels already stored matching from the beginning label, strip them to the end
// if it's not found, then store this as a new label
for label_idx in &labels_written {
// this method on encoder is designed to search all stored (see name_pointers mentioned above)
// and if there is any matching return they're offset (we only ne the start index for that)
let label_ptr: Option<u16> = encoder.get_label_pointer(*label_idx, last_index);
if let Some(loc) = label_ptr {
// We found a matching label, reset back to the
// beginning of this label, and then write the pointer...
encoder.set_offset(*label_idx);
// chop off the labels that we had already written to the buffer
encoder.trim();
// write out the pointer marker
// or'd with the location which shouldn't be larger than this 2^14 or 16k
encoder.emit_u16(0xC000u16 | (loc & 0x3FFFu16))?;
// we found a pointer don't check the rest of the labels
// (they are all contained at the end of that pointer)
return Ok(());
} else {
// no existing label exists, store this new one.
encoder.store_label_pointer(*label_idx, last_index);
}
}
// ...
}
The Finish Line
So after all of these changes, did we achieve our goal?
test trust_dns_udp_bench ... bench: 68,173 ns/iter (+/- 11,699)
and BIND9 (rerunning benches to make sure there was nothing accidentally in the Client that would have favored TRust-DNS)
test bind_udp_bench ... bench: 69,576 ns/iter (+/- 3,620)
Now the +/- is obviously a problem with TRust-DNS, and some point it would be great to make that more consistent. Is it an honest claim that TRust-DNS is faster than BIND9? For this simple test case, TRust-DNS is consistently faster than BIND9. But is it fair? Not really, BIND9 still has many more features than TRust-DNS, also there are many other configurations where we may not be faster, such as TCP based requests, dynamic update, DNSSec record signing, etc. For querying www.example.com of type A from a local server, I do feel confident in claiming we are faster.
I would like to go back and cleanup some other things (like I mentioned at the beginning). But with the help of measurements they weren't necessary to achieve this goal, so those can be done at a later date.
Thank you!
Making all these improvements required a lot of API changes, and became super ugly at different points. While I'm happy to have achieved my goal, it took me a while to clean up the code. I posted this tweet, a while ago. It's taken me quite a while to clean up all the changes so that I could submit them to the library (at which point I came back and edited this post). This was a slog to say the least.
One thing that happened while I was working on this change, @little-dude submitted a new PR which looks to have shaved off approximately another microsecond in #311, without which I don't think we'd have beaten BIND9. Thanks for helping me on this quest!
Thank you for reading this meandering post, I hope you enjoyed it. I definitely enjoyed digging into these issues in the code. It's in the dark corners of software that past decisions continue to haunt.
Happy New Year!
Thank you to my beautiful wife, Lyndsey, for editing this post
- 1) About the Measurements
I'm not being scientific here, so don't get up in arms if my methods aren't perfect. You're welcome to reproduce these results or improve the methods. Everything is publicly available. Rust has a nice benchmarking testing facility (requires nightly as of the time of this writing). I wrote a wrapper for launching the TRust-DNS or BIND9 named binaries. These are loaded with the same zone configuration file; this is not fancy. What I'm interested in is the round-trip time of a UDP DNS request. In the future more benches can be added for things like dynamic update, zone transfer, zone signing, concurrency, etc. The config.log output matches the one I used for building the BIND9 binary. If you think I should change any of that, let me know.
To be clear, the client being used for these measurements is consistent between the two servers. The only thing we should be measuring is the time it takes the client to send and receive a response from the server being tested. The query is simply for the A records with the name www.example.com. I don't believe I've done anything that would give either BIND9 or TRust-DNS a bias. Also a big note here: I wrote this post while working through these changes. I've been working on this in my spare time over the course of a month. During that time a few OS updates came out, and the performance of both BIND9 and TRust-DNS suffered as a result of those OS upgrades. I had planned on tracking the improvement each change had on the overall benchmark performance, but it wasn't possible because those OS upgrades also caused each server to have overall worse performance. Approximately 5µs were lost due to the recent macOS updates. All of the changes in this post are in this PR: #317. If you notice poor verb tense agreement throughout this post, the reason is that I tried many different options, reverted many and continued in different directions (I hope it doesn't distract too much from the content).
-
2) I received a lot of great feedback on my lack of punycode support here: https://www.reddit.com/r/rust/comments/7my0m0/making_trustdns_faster_than_bind9/. It's clear that I need to drop support for UTF8 from the wire, as much as it pains me to have to support this backward compatible format. #321 is now open on the project for this, and maybe I'll work on that next.
-
3) See previous article, They're not Generics; they're TypeParameters