FSM, what?
For anyone who has studied Computer Science, finite state machines are drilled into your head without mercy (or should have been, go ask for you $$$,$$$'s back if these were not drilled into your head). The first CS class I took in college was basically all FSM's, DFA's (deterministic finite automaton) and Turing machines. I don't want to get into the difference between all of these, I'm only going to refer to FSM's. In this example I'm more specifically defining a DFA, as all of the states are known, and there is a begin and end.
Ok, but why is this important? FSM's can simplify problems where you have a known input and known outputs. Specifically what I want to use one for in this example is parsing, boring old parsing. It actually wasn't until I was in the industry that I truly began to appreciate how much simpler and more maintainable your code became if you took the time to define state machines to determine how to move from one state to another.
Background
Firstly, I'm still somewhat new to the Rust language, so when a "real" Rust person reads this, they'll probably complain that I've done xyz wrong, or should do it another way. Let me know! I'd love to understand what I could be doing better. I've been searching for a meaty project to work on to hone my skills in this language, and then I finally found one; It seems like there are security advisories that come out around DNS and specifically Bind all the time. Here is the list of all known Security Advisories in Bind9. Reading through some of the issues made me think, wtf, I'll just write a new DNS server in Rust, b/c you know, why not and it will be safe implicitly, right? While doing that, I was writing the parsers for the binary record data from the DNS rfc's and fell on a really nice way of doing FSM's in Rust.
Now in Java I've used lots of different FSM generators, because I wanted strong language guarantees, for reference, my favorite right now was written by a friend of mine and is annotation based called Tron. This is useful because Java's enums and other basic constructs are not quite as expressive as some of the expressions you can make in Rust.
On to the FSM!
The definition of what we need to parse from RFC1035:
3.1. Name space definitions
Domain names in messages are expressed in terms of a sequence of labels.
Each label is represented as a one octet length field followed by that
number of octets. Since every domain name ends with the null label of
the root, a domain name is terminated by a length byte of zero. The
high order two bits of every length octet must be zero, and the
remaining six bits of the length field limit the label to 63 octets or
less.
To simplify implementations, the total length of a domain name (i.e.,
label octets and label length octets) is restricted to 255 octets or
less. Although labels can contain any 8 bit values in octets that make up a
label, it is strongly recommended that labels follow the preferred
syntax described elsewhere in this memo, which is compatible with
existing host naming conventions. Name servers and resolvers must
compare labels in a case-insensitive manner (i.e., A=a), assuming ASCII
with zero parity. Non-alphabetic codes must match exactly.
There are some more sections that provide details on things like pointers, you can read the spec if you want. Here are the states (I used http://madebyevan.com/fsm/ to build this, which doesn't have edge avoidance so I added some extra states to keep the lines in order):
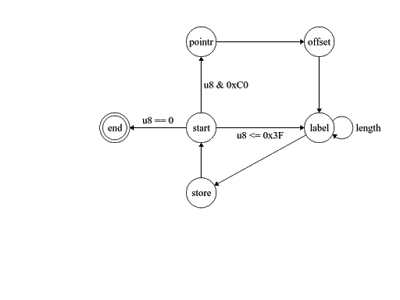
This state diagram basically represents the above, so I decided to translate this (minus the 'offset' and 'store' states) to Rust enums.
This ended up being pretty elegant. but first a side note on enums in Rust.
'enum' really?
So I've noticed this come up in discussions online a few times now. With questions like, "how do you enumerate a Rust enum?" (which has a really funny answer, IMO): You can't! Wait what? You can't enumerate a Rust enum? Why is it called an enum? No, seriously, I don't have an answer to this, why was it called 'enum', when you can't enumerate it's values (other then writing them in order, you can't in code treat them as an array or series as you can in other languages, Java/C/C++ to name a few).
I'm sure someone has an answer to that, but in the mean time I needed to clarify them in my mind. I think they should have been called 'union's because that is what they are most closely related to. In C a union is a data type which which occupies enough memory space to only hold the largest member of the union, but what C doesn't give you is a way to know which thing in that union it really is! (read more here: C unions)
What's cool in Rust is that it does tell you what's stored in the, ahem, enum. So you can write matching (or destructuring) logic like this:
if let MyEnum::Type1 = my_var {
do_something_really_awesome();
}
Which is very powerful and cool.
FSM Now!
Ok so now for the super awesomeness of Rust. My enum is going to have four states, LabelLengthOrPointer == start, Label, Pointer, Root == end.
/// This is the list of states for the label parsing state machine
enum LabelParseState {
LabelLengthOrPointer, // basically the start of the FSM
Label(u8), // storing length of the label
Pointer(u8), // location of pointer in slice,
Root, // root is the end of the labels list, aka null
}
Ok, now for the code to run the state machine:
/// parses the chain of labels
/// this has a max of 255 octets, with each label being less than 63.
/// all names will be stored lowercase internally.
/// This will consume the portions of the Vec which it is reading...
pub fn parse(slice: &mut Vec<u8>) -> Result<Name, FromUtf8Error> {
let mut state: LabelParseState = LabelParseState::LabelLengthOrPointer;
let mut labels: Vec<String> = Vec::with_capacity(3); // www.example.com
// assume all chars are utf-8. We're doing byte-by-byte operations,
// no endianess issues...
// reserved: (1000 0000 aka 0800) && (0100 0000 aka 0400)
// pointer: (slice == 1100 0000 aka C0), then 03FF & slice = offset
// label: 03FF & slice = length; slice.next(length) = label
// root: 0000
loop {
state = match state {
LabelParseState::LabelLengthOrPointer => {
// determine what the next label is
match slice.pop() {
Some(0) | None => LabelParseState::Root,
Some(byte) if byte & 0xC0 == 0xC0 =>
LabelParseState::Pointer(byte & 0x3F),
Some(byte) if byte <= 0x3F => LabelParseState::Label(byte),
_ => unimplemented!(),
}
},
LabelParseState::Label(count) => {
labels.push(try!(util::parse_label(slice, count)));
// reset to collect more data
LabelParseState::LabelLengthOrPointer
},
LabelParseState::Pointer(offset) => {
// lookup in the hashmap the label to use
unimplemented!()
},
LabelParseState::Root => {
// technically could return here...
break;
}
}
}
Ok(Name { labels: labels })
}
code here.
So I'll just point out a couple of things that Rust does for us here: 1) guarantee that all states are considered 2) that each state has a result because of the assignment to the state. You'll notice that there are some unimplemented!()'s in there, that's because this is a work in progress, but I was so excited about how easy it was to write an FSM in Rust with just the standard language semantics, that I just had to share.
Basically, the sweet sauce here is that the 'state' can carry context implicitly in the enum as part of it's tuple definition. You can obviously make that more complex than what I did here, but this was such a simple and elegant solution to a common problem.
Conclusion
Rust continues to impress me while learning it. There are definitely some oddities like enum's being called enum's when they really are something else. Also, I continue to fight the compiler on mutability around ownership, etc. It's not that I don't get the ownership model, I do... it's that after working with a GC in Java for so long, I have to train myself to think about it each time I pass a reference to something, and as far as I can tell 90% of the time I'm getting it wrong the first time.
Anyway, getting back to hacking DNS now.